![]()
Contenu : |
Une image contient des objets qui peuvent être la cible de recherches faites dans une collection d'images. A un objet on peut faire correspondre
Un objet comportant beaucoup de pixels, il peut être utile de travailler par groupes de pixels ou cellules obtenues par un quadrillage de l'image. Si une image est de dimension a x b, une cellule aura les dimensions m x n telles que a mod m = 0 et b mod n = 0. Une cellule contient donc m x n pixels. La division de l'image en cellules définit la résolution de l'image. Dans ce cas le descripteur de caractéristiques de bas niveau portera sur les cellules et non plus sur les pixels ; il portera sur moins de données : position moyenne de la cellule, couleur moyenne de la cellule.
Un objet est un ensemble de points (ou de cellules) tel que si P et Q sont deux points (ou cellules) de l'objet, on peut passer de P à Q par incrémentation des coordonnées..
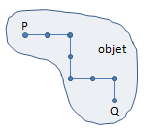
Si l'objet est rectangulaire, la définition est plus simple : P(x,y) ∈ objet si xmin ≤ x ≤ xmax et ymin ≤ y ≤ ymax.
Une base de données image, compte tenu des définitions précédentes, sera caractérisée par
Une image comporte un nombre important de pixels ou même de cellules. Il est utile de réduire le nombre de données à manipuler en compressant une image par un algorithme de transformation qui fera passer d'une image de dimensions (p1, p2) à une image compresées de dimension (h1, h2). L'algorithme de transformation ne doit pas demander un temps de calcul trop long.
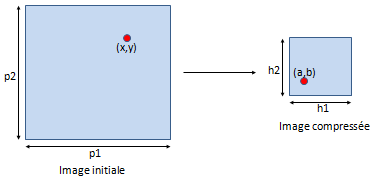
Citons deux méthodes usuelles d'obtention d'images compressées :
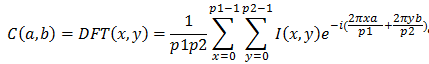
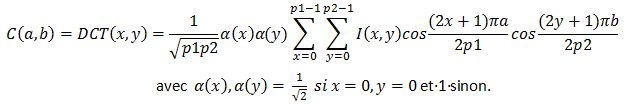
Ces deux transformations sont inversibles. toutefois, les algorithmes de compression comprennent généralement d'autres traitements comme la quantification qui n'est pas une opération inversible. La transformation inverse ne redonnera pas l'image initiale mais une image avec perte d'information.
Une autre propriété des DFT et DCT est la conservation de la distance euclidienne.
Revenons sur le concept de région dans une image. Comment détermine-t-on ces régions ? Elles peuvent être obtenues par un procédé de segmentation (on les appelle alors des segments) basé sur une propriété d'homogénéité (par exemple, pixels dont le niveau de rouge est compris entre 0 et 127 dans une échelle allant de 0 à 255).
Pour comprendre le procédé de segmentation, il faut définir ce que l'on entend par région connexe. C'est un ensemble de cellules tel que la distance entre deux cellules contigues (partageant une arête) de cet ensemble est 1.
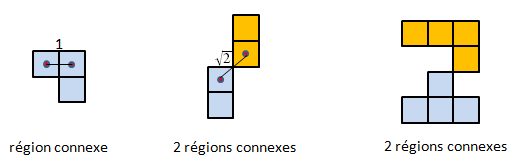
Une propriété d'homogénéité utilisée dans le procédé de segmentation fournit une réponse booléenne : oui ou non. On pourra alors définir un segment de la manière suivante :
1 - On part d'un point (cellule) qui vérifie la propriété d'homogénéité (réponse : oui). Il constitue le départ d'un segment R.
2 - On cherche si ses voisins Nord, Est, Sud, Ouest vérifie la propriété d'homogénéité. Si oui ils sont ajoutés à R.
3 - On recommence 1 avec l'un des nouveaux points de R. Quand on ne trouve plus de points, on a définit un segment R
En partant d'un autre point non sélectionné, on peut ainsi définir un autre segment et ainsi de suite jusqu'à ce que tous les points de l'image aient été sélectionnés.
exemple :
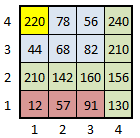 |
Propriété d'homogénéité : niveau de rouge compris entre 0 et 127 (les niveaux sont indiqués sur la figure) 4 segments : |
Les segments obtenus forment une partition de l'image : leur réunion donne l'image complète et les segments sont disjoints deux à deux.
Comment, dans une base de données images, trouver les images qui "ressemblent le plus" à une image donnée ? Il y a deux démarches générales pour résoudre cette requête : la démarche métrique (très utilisée) et la démarche par transformation.
Dans la démarche métrique, on considère un ensemble W d'objets Oi ayant les caractéristiques de cellules p1, p2, ...pn. Une cellule j d'un objet Oi aura les caractéristiques (xj, yj, v1j, v2j, ...., vnj). Si l'objet Oi est de dimansions w x h (on le supposera rectangulaire), il y a wh caractéristiques qui correspondent chacune à un point dans un espace à n+2 dimensions. un objet est donc représenté par un ensemble de points dans cet espace.
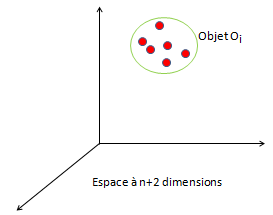
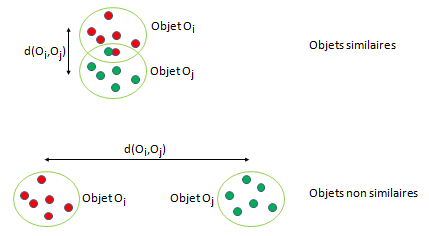
Dans cet espace, on définit une distance. Rappelons qu'une distance d(x,y) est un nombre réel non négatif satisfaisant les propriétés suivantes
d(x,y) = d(y,x)
d(x,x) = 0
d(x,y) ≤ d(x,z) + d(z,y)
Il y a plusieurs façons de définir une distance. La plus connue est la distance euclidienne définie à partir du théorème de Pythagore d2 = a2 + b2. Appliquons la distance euclidienne à des objets en couleur dont les propriétés caractéristiques sont le niveau de rouge, le niveau de vert et le niveau de bleu. Pour un objet Oi, on aura donc wh caractéristiques du type (x, y, nivR(x,y), nivV(x,y), nivB(x,y)) où nivX(x,y) prennent des valeurs de 0 à 255. En supposant que la dimension d'un objet est w x h, la distance entre deux objets Oi et Oj pourra être définie par
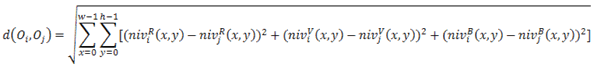
Evidemment un tel calcul peut être long. C'est pourquoi on utilise généralement une fonction fe d'extraction de caractéristiques qui vise à remplacer l'ensemble de points (dans un espace à n+2 dimensions) représentant un objet par un seul point dans un espace à s dimensions (s << n+2). C'est une forme de compression où les transformées DFT et DCT peuvent être utilisées puisqu'elles conservent la distance euclidienne.
Dans la démarche de transformation, on applique le principe suivant consistant à transformer un objet pour le faire ressembler à un autre et à mesurer le "coût" correspondant. Plus le coût est élevé plus les objets concernés sont dissemblables. Une transformation peut être une combinaison de transformations élémentaires : translation, rotation, réduction, agrandissement mais aussi extension (ajout de formes), excision (suppression de formes), coloration (changement de couleur).
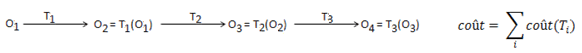
Il peut y avoir plusieurs chaînes de transformations qui mènent au même résultat. Dans ce cas, la mesure de la dissimilarité est le coût minimum des coûts de Τ(O, O')UΤ(O', O) où Τ(O,O') est l'ensemble de toutes des transformations qui font passer de l'objet O à l'objet O'.
Reamarquons que
On peut indexer une base de données images avec des arbres R. ceci est justifié quand les objets sont délimités par des rectangles. On commence par créer une table relationnelle OBJET
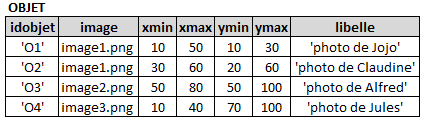
Bien que les objets délimités par des rectangles soient dans des images différentes, la construction de l'arbre R s'effectue comme si ils étaient dans la même image :
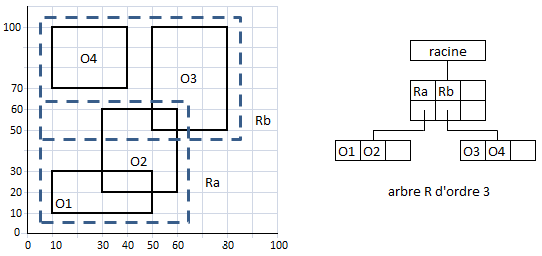
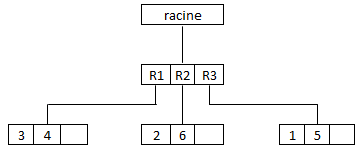
A partir des coordonnées des objets dans la table OBJET, on peut retrouver un objet en circulant dans l'arbre R depuis la racine.
![]()
On sait qu'une vidéo numérique se compose
Nous ne considérerons pas ici le problème de la synchronisation du son avec les images. Nous ferons comme si la vidéo était muette. Nous reviendrons sur la question du son dans la partie suivante.
Le standard le plus utilisé en vidéo appartient à la famille MPEG. Dans MPEG-1, la séquence d'images comporte trois types d'images I, P, B :
![]()
I est une image "intra" obtenue par enregistrement direct de la caméra ; P est une image calculée à partir de l'image I qui la précède ; B est une image calculée par interpolation à partir des images P ou I les plus proches. Les images sont dans un format compressé (JPEG).
Quoi qu'il en soit, on peut considérer une vidéo comme une suite d'images numérotées dans le sens de la visualisation, ce qui nous suffira dans ce qui suit.
![]()
Une vidéo comporte, comme les images, des objets (personnes ou choses). Le fait nouveau ici est qu'elle comporte aussi des activités. Prenons l'exemple suivant :
 |
 |
 |
la voiture sort du garage et roule sur la route |
la voiture fait demi-tour |
la voiture rentre au garage |
images 1 à 99 |
images 100 à 199 |
images 200 à 299 |
Sur cet exemple, les objets peuvent être : le garage, la voiture. Les activités peuvent être "sortie du garage", "demi-tour", "rentrée au garage".
Un objet possède des caractéristiques comme dans le cas des images. cependant on peut distinguer les caractéristiques indépendantes des images de la vidéo et des caractéristiques dépendantes des images de la vidéo. Un schéma d'objet sera donc de la forme (cd, ci) où cd désigne les caractéristiques indépendantes et ci les caractéristiques dépendantes. Une caractéristique ne peut être à la fois indépendante et dépendante. Derrière cd et ci il y a en fait une série de caractéristiques ou propriétés repérées par un nom et une valeur. Un objet particulier est alors défini par un triplet (oid, os, prop). oid est l'identifiant unique de l'objet qui permet de le discerner des autres objets. os est un schéma d'objet. prop qui correspond aux propriétés de l'objet suivant le schéma os peut être défini de la manière suivante : pour chaque propriété ci, il y a au moins une propriété valuée nomprop = valeurprop ; pour chaque propriété cd, il y a au moins une propriété de la forme nomprop=valeurprop IN f où f est le numéro d'une image de la vidéo. Dans notre exemple, on aura
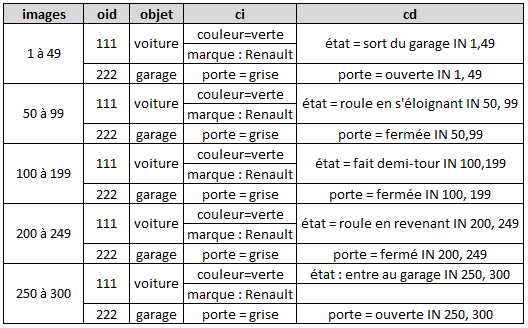
Passons maintenant aux activités en adoptant une démarche proche de la précédente. Une activité se réfère à un schéma d'activité qui donne une liste de propriétés comme (nomprop, valeur). Une activité sera alors définie par une suite de paires (nomprop, valeur). Dans notre exemple on pourra avoir pour l'activité "circuler" : (entrer-sortir, voiture), (rouler, voiture), (faire_demi_tour, voiture).
Résumons-nous. Supposons que la vidéo comporte q images. Le contenu de la vidéo est une série de triplets (obj, act, mapping) où obj est un objet, act une activité et mapping la correspondance entre une image de la vidéo et un couple objet-activité. Exemple de triplet : (111, rouler, 75) ce qui signifie que dans l'image 75 la voiture d'oid 111 roule. Bien entendu comme les vidéos comporte un très grand nombre d'images, cela fait beaucoup de triplets. On étudiera plus loin ce problème. Une base de données vidéo pourrait alors avoir la forme suivante
![]()
où contenu est un pointeur vers un contenu comme défini ci-dessus (série de triplets), idvidéo un identifiant repérant une vidéo particulière, nom_vidéo, le nom du fichier image, numéro image, le numéro de l'image correspondant au contenu, annotations des métadonnées (auteur, sujet, date enregistrement, droits, ....) et stockage un pointeur vers les structures de stockage (disques, CD, bande, ...).
Comme on le sait, le nombre d'images d'une vidéo est très grand. c'est pourquoi il vaut mieux parler de "morceaux" de vidéo ou segments en remplaçant le triplet (obj, act, mapping) par un triplet où mapping n'est plus la correspondance entre une image et une couple objet-activité mais une correspondance entre une séquences d'images et un couple objet-activité. Pour indexer ce nouveau contenu, on peut faire appel aux arbres binaires. Négligeons pour l'instant les activités et supposons que nous avons dans le temps, image par image, l'apparition/disparition des objets 1, 2, 3 ci-dessous :
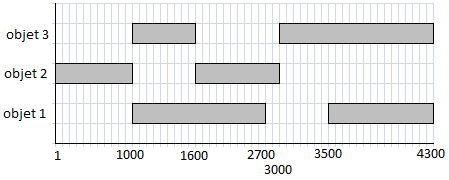
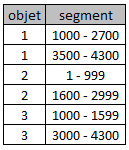
A partir de cette situation, on pourra définir les segments par dichotomie : la racine correspond au segment représentant toute la vidéo (1 - 4300) mais en divisant par 2 successivement on va tomber sur des nombres impairs (que l'on ne pourra pas diviser par 2). C'est pourquoi on ajuste le nombre d'images à la puissance de 2 la plus proche (soit ici 8192 = 213) en ajoutant des images fictives. La racine correspondra donc au segment (1-8192). Ses deux descendants correspondront aux segments (1 - 4096) et (4097 - 8192) et ainsi de suite.
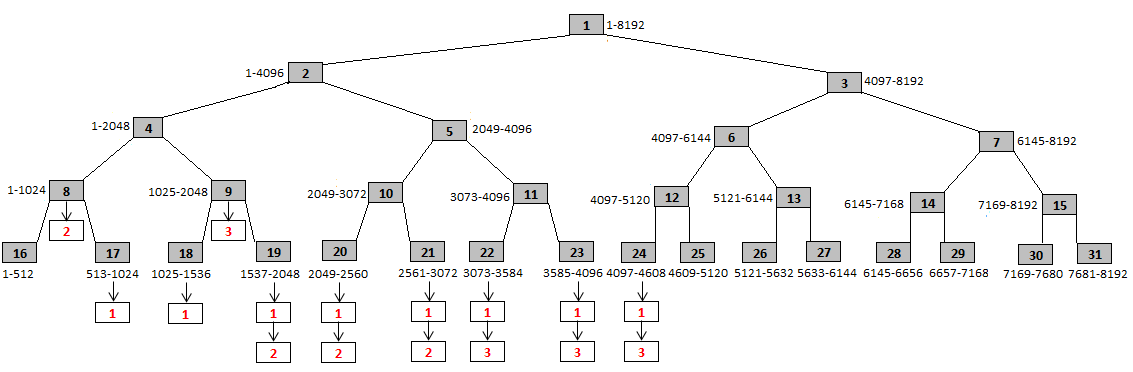
Pour chaque noeud, la plage d'images est indiquée. Si un objet est présent dans une plage, un pointeur est placé vers l'objet correspondant sur le noeud dont la plage d'images le contient (totalement ou partiellement). On a ainsi segmenté la vidéo en faisant correspondre à chaque segment les objets correspondants. On pourrait faire de même pour les activités.
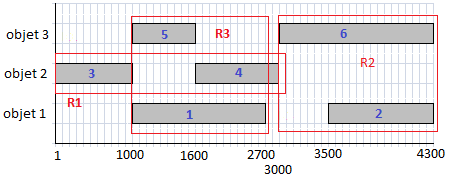
On peut aussi utiliser les arbres R pour répertorier les séquences où des objets interviennent. Les segments sont alors ces séquences, numérotées ci-dessous de 1 à 6. On peut définir des rectangles englobant certains segments, ici R1, R2, R3
![]()
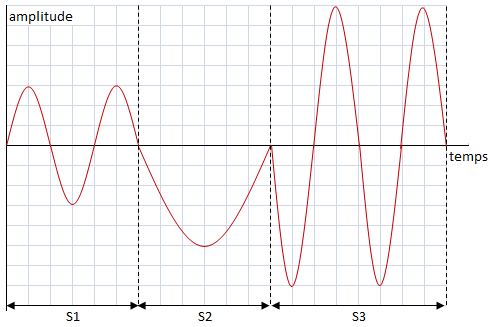
Le son est représenté par une grandeur continue variant au cours du temps qui constitue le signal audio. Le théorème de Fourier a montré qu'un tel signal peut être considéré comme la superposition de signaux élémentaires sinusoïdaux se caractérisant chacun par une amplitude et une fréquence données.
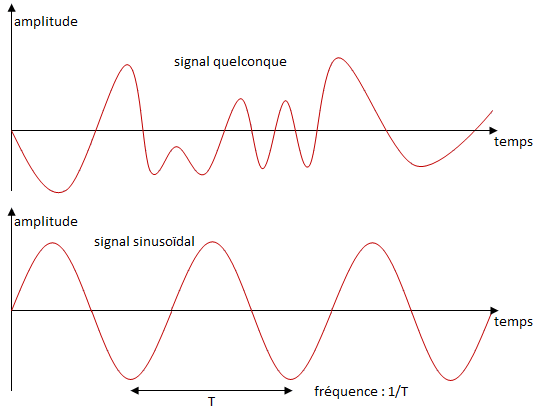
Les schémas ci-dessus correspondent au son analogique. Pour passer au son numérique, il faut effectuer trois opérations :
Plus f est grand, plus le son numérisé se rapprochera du son analogique. mais cela a un coût. Une fréquence f = 44 Khz correspond à la prise de 44000 échantillons par seconde, donc 44000 nombres pour seulement une seconde de son. Par ailleurs, plus n est grand plus la mesure quantifiée sera proche de la mesure analogique. les valeurs courantes sont n = 8 (valeurs de 0 à 255 exprimées sur 8 bits) ou n = 16 (valeurs de 0 à 65535 exprimées sur 16 bits).
En définitive, le son numérisé est une suite de valeurs, un peu comparable àl a suite d'images d'une vidéo
![]()
Comme pour la vidéo, on peut découper un signal en segments suivant plusieurs procédés :
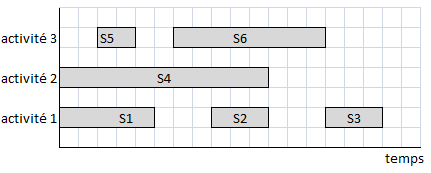
On obtient dans ce cas des segments qui peuvent se superposer dans le temps.
Le processus de découpage peut être automatisé.
Evidemment, le nombre des segments peut être grand et on peut ici aussi appliquer une compression basée sur des transformations comme DFT et DCT vues plus haut.
Une fois la segmentation achevée, on peut utiliser des techniques d'arbres pour indexer chaque segment.
![]()
Choisir la bonne réponse dans les questions suivantes. Une bonne réponse rapporte 1 point, une mauvaise - 1 point. Le choix d'une réponse n'est pas obligatoire. Il peut y avoir plusieurs bonnes réponses.