![]()
Contenu : |
dernière version : octobre 2012
On peut considérer un document texte comme une série de chaînes de caractères. En particulier une chaîne peut être un critère qui servira aux recherches : recherche de l'occurrence de cette chaîne dans plusieurs documents. Toutefois, deux difficultés se présentent :
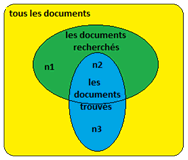
Ces deux problèmes affectent évidemment la performance d'un système de recherches. Une recherche de documents peut correspondre au schéma ci-dessous :
Il existe cependant des méthodes élaborées pour pallier ces difficultés. L'une de ces méthodes s'appelle LSI (Latent Semantic Indexing). Deux notions essentielles sont rattachées à cette méthode : la précision (precision) et le rappel (recall).
Soit n1 le nombre de documents recherchés mais non trouvés, n2 le nombre de documents recherchés et trouvés, n3 le nombre de documents trouvés mais non recherchés. Pour une recherche donnée, la précision P et le rappel R sont définis par
![]()
On ajoute 1 au numérateur et au dénominateur pour éviter une division par zéro. Ces deux paramètres sont nécessaires car
Bien entendu, dans un texte, tous les mots ne sont pas porteurs d'une égale importance. les mots comme le, la, les, du, un, une, des, et, avec, comme, car, puis, ensuite, .... sont en quelque sorte inutiles dans une recherche (pour les recherches courantes évidemment). De même le mot "animal" dans un texte relatif à la zoologie n'est pas pertinent et le mot "ordinateur" dans un texte relatif à l'informatique n'est pas pertinent non plus. On peut placer les mots non pertinents dans une liste spéciale appelée stop list.
Par ailleurs, on peut retrouver une partie d'un mot dans différents mots ; par exemple les mots voyage, voyages, voyageur, voyageuse, voyageurs, voyagiste, voyagistes ont une même racine "voyag" et peuvent être tous remplacés par cette racine.
Donc ayant éliminé les mots de la stop list et remplacé des mots par leur racine, on peut établir une statistique des mots rencontrés dans plusieurs documents ce qui conduit à un tableau :
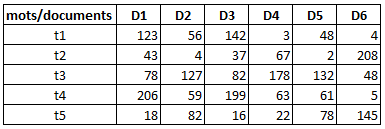
où D1, D2, ... sont des documents texte et t1, t2, .... sont des mots.
![]()
Cependant les documents n'ont pas la même longueur. Pour prendre en considération cet important aspect, il faut normaliser les colonnes. On peut le faire avec la relation
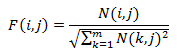
où N(i,j) est le nombre de mots ti dans le document Dj.
ce qui donnerait le résultat suivant :
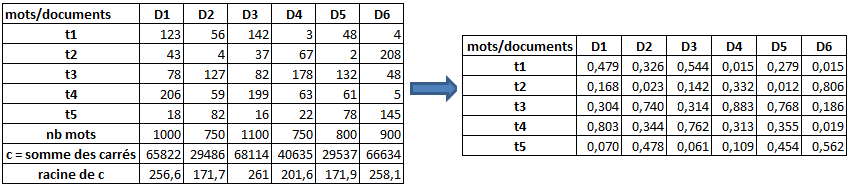
On peut alors remplacer un document par la colonne correspondante considérée comme un vecteur Dj et un mot par la ligne correspondante. On désignera par la suite par f(i,j) le fréquence du mot ti dans la document Dj obtenue avec le procédé précédent.
La similarité entre deux documents est définie par l'expression Sim(dp, dq) :
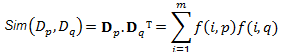
On peut considérer l'expression de la similarité comme le produit scalaire de deux vecteurs (représentant les documents) de longueur 1. Elle mesure donc le cosinus de l'angle entre les deux vecteurs.
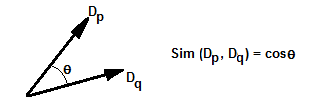
Le tableau suivant donne les similarités des documents de notre exemple :
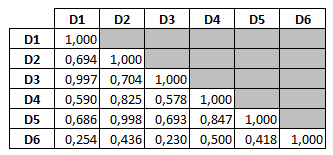
On peut ainsi constater que les documents D1 et D3 sont "proches", de même que les documents D2 et D5.
Supposons que l'on effectue une recherche Q de l'occurrence de plusieurs mots dans l'ensemble des documents. On obtiendra une colonne supplémentaire q au tableau précédent et on recherchera la proximité de chaque document avec cette nouvelle colonne. Un exemple montre comment le vecteur q peut être obtenu. Supposons que l'on souhaite trouver les documents pour lesquels figurent les mots t1 et t4. On posera alors a priori

q représente un document fictif (pseudo document) . La recherche définie par Q consiste alors à chercher la similarité entre q et chaque document :

On constate que les documents D1 et D3 sont ceux qui correspondent le mieux à la requête Q.
![]()
Notre exemple ne correspond pas à la réalité dans laquelle le nombre de mots et le nombre de documents sont très grands. La matrice F d'éléments f(i,j) est une très grande matrice et sa manipulation nécessite de nombreuses opérations, de la place mémoire et un important temps de traitement. Pour réduire la dimension de la matrice F et donc le temps de traitement et le volume de stockage, des méthodes sont employées. La plus connue est la méthode LSI (Latent Semantic Indexing).
La méthode LSI s'appuie sur une technique mathématique appelée SVD (Singular Value Decomposition) qui consiste à remplacer en premier lieu la matrice F d'éléments f(i,j) par le produit de trois matrices
UxSxVT
où S est une matrice carrée diagonale dont les éléments de la diagonale principale sont décroissants du haut vers le bas et dans un second temps à réduire la matrice S (et donc les matrices U, V et par voie de conséquence F) en éliminant les éléments les moins significatifs.
Un résultat mathématique montre que la matrice F de dimension mxn (m lignes, n colonnes) peut s'écrire
F = UxSxVT
où
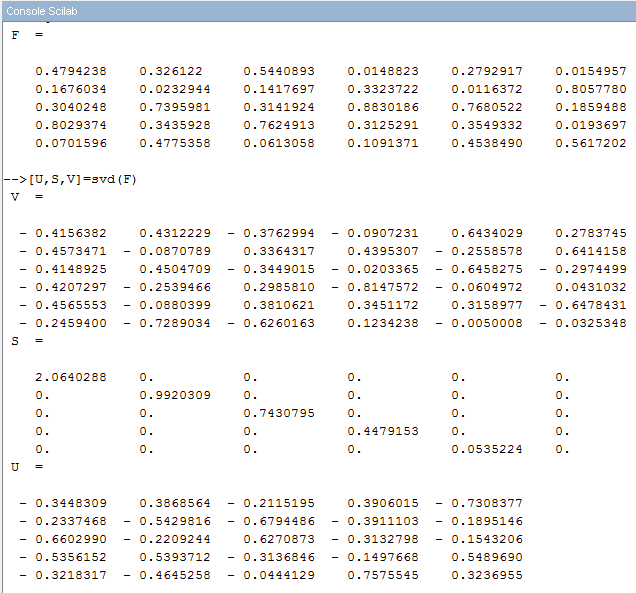
Les logiciels de mathématiques proposent le calcul de cette décomposition. Par exemple Scilab (http://www.scilab.org/fr) fournit les résultats suivants pour le tableau précédent :
On a bien

On remplace maintenant la matrice S par une matrice S* de dimension moindre en ne gardant que les éléments diagonaux non négligeables. Par exemple, sur l'expression ci-dessus, on négligera dans S le dernier élément très négligeable par rapport aux autres, ce qui implique aussi une réduction des matrices U et V (pour que la multiplication puisse se faire) qui deviennent U* et V* :
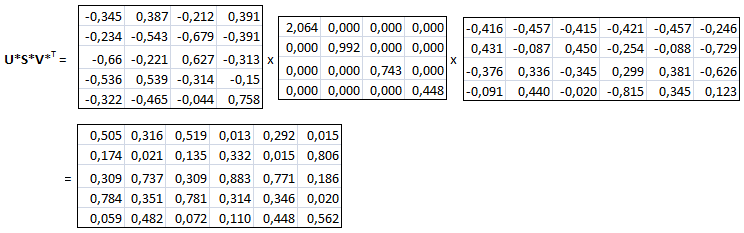
Rappelons que si la matrice F initiale (que l'on doit retrouver ici) est de dimensions qxm (q lignes, m colonnes), si la matrice s* est de dimensions p x n , la matrice U* doit être de dimensions q xp et la matrice V* de dimensions m x n (donc V*T de dimensions n xm).
Le résultat obtenu est une approximation de F. Nous avons cependant moins de calculs à faire dans la multiplication matricielle. Pour étudier la similarité de documents ou les documents qui se rapprochent le ,plus d'une requête, la réduction permet un gain de temps calcul appréciable.
L'interprétation de cette décomposition de la matrice F (matrice mot-document) est donnée dans les applications suivantes :
application 1 : comparaison de deux documents
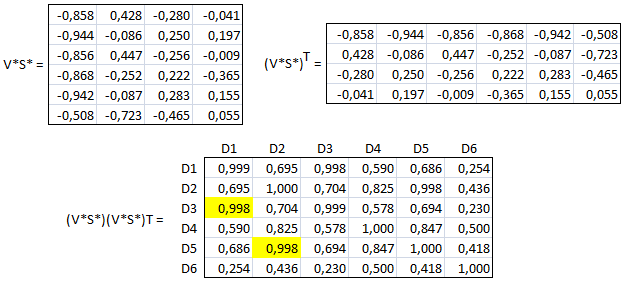
Pour obtenir la ,similarité entre deux documents on effectue les produits Sim(Dp, Dq) ce qui conduit au produit matriciel FTF = (USVT)T(USVT) = VSTUTUSVT = (VST )I(SVT) =(VST )(VST )T . En version réduite l'expression correspondante est F*TF* = (V*S*T)(V*S*T)T = (V*S*)(V*S*)T ce qui signifie que F* (approximation de F) est représentée par (V*S*)T . Les colonnes de cette matrice D = (V*S*)T sont donc représentatives des vecteurs documents (mais comportent moins d'éléments). Appliquons à notre exemple :
On constate que les résultats sont très proches de ceux obtenus par le calcul global mais ici les calculs sont moins longs. On note toujours la forte similarité entre D1 et D3 et entre D2 et D5.
application 2 : recherche de documents répondant à une requête Q
Supposons que l'on recherche les documents qui se distinguent par la présence des mots t1 et t4. On peut alors construire un pseudo-document représenté par le vecteur q que l'on normalise à 1, Comme dans le cas général, on va chercher la similarité avec les vrais documents D1 à D6.
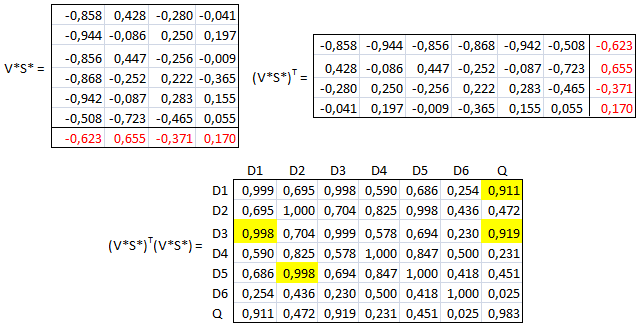
On est alors ramené au cas précédent en cherchant la similarité de q avec les documents D1, D2, etc. On va donc être amené à ajouter à la matrice V*S* la ligne QS* telle que qT = U*S*Q*T (par analogie à F*=U*S*V*T). On en déduit que q = QS*TU*T = QS*U*T ou QS* = qU*. Cette dernière expression permet de calculer QS* :
La nouvelle matrice V*S* augmentée de la ligne QS*, sa transposée et le produit des deux, sont alors
La dernière matrice est celle des similarités. On retrouve un résultat précédent à savoir que les deux documents répondant au mieux à la requête sont D1 et D3.
![]()
Ce type d'indexation est celui utilisé dans la classification comme par exemple la classification des animaux représentée ci-dessous
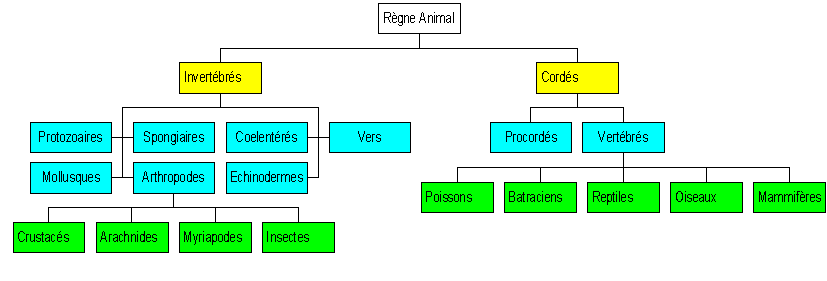
source : rvinchon.pagesperso-orange.fr
Pour chercher un animal, on part de la racine puis on fait jouer un critère, puis un autre, etc..
Les arbres TV (telescopic vector) s'appuient sur cette idée en faisant jouer des dimensions que l'on appelle dimensions actives. Par exemple, si on considère un document représenté par un vecteur (0,24 0,14 0,96) et si on recherche des documents voisins, on pourra rechercher d'abord les documents dont la composante 3 (3ème dimension) est proche de 0,96, puis on pourra raffiner la recherche en se focalisant sur les dimensions 1 et 2.
Formellement, un arbre TV se caractérise comme les arbres R par des noeuds représentant des régions, la région d'un noeud père englobant les régions des noeuds fils. Il y a deux paramètres à spécifier pour un arbre TV : le nombre maximum nmax d'enfants que peut avoir un noeud et le nombre maximal α de dimensions actives (avec 0 < α ≤ k) où k est le nombre de dimensions de l'espace de recherche. On note TV(k, nmax, α).
On ajoute les règles suivantes :
Un document , comme on l'a vu précédemment, peut être représenté par un vecteur (ou un point) dans un espace de dimension k (k étant le nombre de mots pris en considération pour comparer des documents). Pour évaluer la proximité de deux documents, on utilise une distance, comme, par exemple la distance euclidienne. Par exemple la distance entre les documents D1 (0,24 0,14 0,96) et D2 (0 0 1) est
![]()
Mais si l'on veut comparer les deux documents seulement sur leur troisème coordonnée (dimension active : 3) , on aura la dimension active
![]()
Considérons une représentation par un arbre TV(5,3,2). Les documents sont caractérisés par rapport à 5 mots et correspondent chacun à un point possédant 5 coordonnées. Un noeud ne pourra avoir au maximum 3 enfants et le nombre maximum de dimensions actives est 2 (sur les 5 possibles). Un noeud aura la physionomie suivante :
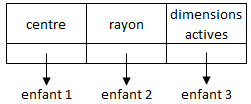
Un tel noeud détermine une région centrée sur le centre indiqué et de rayon indiqué. Tout point de cette région doit vérifier, si les dimensions actives sont par exemple 2 et 3, la condition d2,3(C, P)≤ rayon.
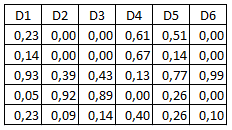
Sans vouloir trop s'attarder sur la théorie des arbres TV, prenons un exemple illustratif uniquement pour montrer l'esprit de la démarche. On utilisera un arbre TV(5,3,2). Supposons que l'on ait 6 documents D1, D2, D3, D4, D5, D6, définis par leurs coordonnées :
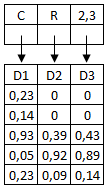
Plaçons d'abord la racine (qui représente tout l'espace) mais que l'on indexe sur les dimensions 2 et 3 (dimensions actives). On peut sans problème loger les documents D1, D2, D3 sous cette racine :
Pour placer D4, on est embêté car il n'y a plus de place car le nombre maximum d'enfants par noeud est 3. Il faut donc effectuer une décomposition en deux noeuds enfants dans lesquels il faudra placer de manière équilibrée les documents D1, D2, D3, D4 (2 par noeud). On choisit les couples en fonction de la distance active pour les dimensions 2 et 3. Le tableau suivant donne cette distance pour tous les documents.
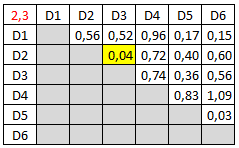
On constate que les documents les plus proches (par rapport à la distance active) sont D2 et D3. On aura donc l'arborescence suivante :
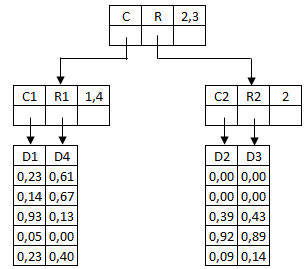
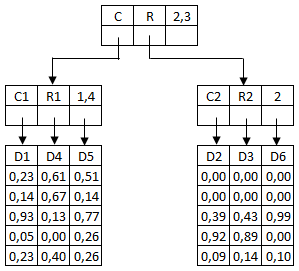
On ne précisera pas ici les centres et les rayons des noeuds pour ne pas compliquer les choses. Nous avons toutefois opté pour une décomposition future pour les dimensions actives 1,4 pour le noeud N1 et 2 pour le noeud N2. Reste à placer D5 et D6. Comme il reste deux places, on n'a pas à décompose pour le moment. Mais où mettre D5 (et donc D6) ? On pourra choisir de mettre D6 avec D2 et D3 (ils sont tous alignés sur l'axe 3) et donc D5 avec D1 et D4.
Choisir la bonne réponse dans les questions suivantes. Une bonne réponse rapporte 1 point, une mauvaise - 1 point. Le choix d'une réponse n'est pas obligatoire. Il peut y avoir plusieurs bonnes réponses.